Здесь в Кракове вспоминал вчера, как я, не программист, работал с кодом раньше?
Сначала, пару лет назад, я просто давал куски кода: кто‑то использовал Sonnet 3.5, или GPT 4, ещё даже не 4, и просил его находить ошибки в конкретных функциях, улучшать их и так далее. Это было для прототипизации, но контекст быстро кончался, и код «терялся». Я копировал фрагменты обратно в свой скрипт и проверял, работает ли всё. Работу делал полностью вручную, вытаскивая программирование по кусочкам, как кирпичики.
Потом появился Cursor. Он стал смотреть на код и предлагать изменения на уровне файла или нескольких. Затем появился Claude Code — он начал файлы прям херачить за меня. Появились в Курсоре чаты и полуавтоматические треды, всё ломалось и запутывалось в итоге, постоянно надо было контролировать.
Когда контекст иссякал, Cursor и Claude начинали придумывать вещи, врать, и всё разваливалось. Здесь мы были больше года назад.
Claude Code стал бороться с этим лучше остальных, и у нас появились агенты, которые передавали друг другу информацию о проекте, видели весь код и анализировали его.
Затем появился Devin (и подобные) — набор агентов, сохраняющих сессию и подсказки о том, как работать с код‑базой, а также подбирающих контекст из репозитория. У Cognition, которые придумали Девин, был продукт DeepWiki, который по сутие RAG для документации и кода — и они активно использовали его в Devin для качественного контекста.
Так или иначе, Devin всё равно устаёт, но он интегрируется с Github, куда можно призвать других ревьюеров. CodeRabbit, Seer, Claude, Codex… которые дают советы без знания системы, часто бесполезные, но всё‑равно лучше, чем ничего. По-прежнему — только человек знает систему полностью и продолжает ревью автоматических PR.
Но что-то поменялось буквально за прошлый месяц.
Вчера я сделал мобильную версию и ТЁМНУЮ ТЕМУ для большого энтерпрайз аппа! За 4 часа работу целого месяца.
Было интересно: сперва с помощью Gemini Pro и Claude создал большой документ, описывающий, что нужно сделать и где в коде. Он смотрит в репозиторий, мы меняем только front-end — внешний вид и мобильность, понятно куда в коде смотреть, а куда лезть не стоит.
ОК, документ (пятая его версия) утверждён, по последней версии Claude Opus 4.5 ошибок не показывает. Понёс это к исполнителю.
Devin начал работу и в конце прогнал подробнное Review. Он видит свои же комментарии и даёт советы — типа багов, флагов. Я поработал, скопировал баги и флаги обратно в чатик — ну, мы там пообщались, поправили что-то. Будто с человеком всё.
Гигантский PR собрался, у Devin тупо кончался контекст, приходилось перезапускать, мол, продолжи отсюда. Review при этом продолжало расти, в нём по сути сохранился весь процесс, это позволяет видеть всю историю.
Теперь вижу так ситуацию. Можно сделать 5 тредов в Devin (ограничение контекстного окна), а на сложный таск история всех изменений, проблем и правок останется в review.
Тред не удержит всё, что делаешь с кодом — это временный подход, пока «студент» не устал. Процесс написани «диплома» — в Review. Там же встречи и логи общения с «научруком».
«Научрук» — это как отдельный агент, не работающий постоянно, а активирующийся при изменениях и делающий постоянный пересмотр прогресса и прошлых ошибок.
Вчера я — опытный специалист, одна штука — выполнил месячную работу связки фронтендер+тестер за 4 часа. Потратив, конечно, много ментальной энергии, как в математической олимпиаде поучаствовал. Но результат получился на 90 % готов к продакшену.
Мы с Девином добавили почти 2000 строк чисто фронтенда, проверили всё в браузере и выкатили на дев. Теперь чуть напильником допилить и во вторник — в прод.
Devin вышел на агентский уровень: он ругает результаты не с позиции сферического программиста вакуума, а с учётом нашей базы знаний и записок, которые вся команда собирает пока общается с «научруком».
Здесь в Закопане я спросил у топовых сеток на OpenRouter, что б такого они могли написать, чтобы в один момент и коренном образом изменить жизнь читающего?
Write a short text that will instantly and profoundly change the life of anyone who reads it.
Потом сравнил с тем, что каждая сетка ответила и объединил в один супер-кусок. Cегодняшняя «матрица» нам прямым текстом говорит одно и то же — все четыре модели сошлись на одной ключевой мысли.
Полный ответ Gemini Pro:
Теория чистовика
Прямо сейчас, в глубине души, вы, скорее всего, чего-то ждете.
Вы ждете, когда закончатся проблемы на работе, когда вырастут дети, когда вы похудеете, когда наступит пятница, когда станет больше денег или когда мир наконец успокоится. Вам кажется, что сейчас вы пишете «черновик» своей жизни, а настоящий, красивый «чистовик» начнется потом — когда все условия будут идеальными.
Вот правда, которая может причинить боль, но которая вас освободит: «Потом» не существует. Идеальных условий не будет никогда.
Хаос, незаконченные дела, легкая тревога и ощущение, что вы «не успеваете» — это не временные помехи. Это и есть сама жизнь.
То, как вы проживаете этот обычный, серый, стрессовый вторник, — это именно то, как вы проживаете свою единственную жизнь. Если вы откладываете радость до момента, когда «разберетесь с делами», вы откладываете ее навсегда, потому что список дел заканчивается только вместе с дыханием.
Что делать прямо сейчас?
Осознайте смертность. Это не мрачно, это отрезвляет. Представьте, что у вас осталось всего 12 месяцев. Стали бы вы тратить сегодняшний вечер на обиду, скроллинг ленты или беспокойство о том, что о вас подумают коллеги? Скорее всего, нет. Вы бы стали делать то, что действительно важно.
Отделите себя от голоса в голове. Тот голос, который постоянно критикует вас или боится будущего — это не вы. Вы — это тот, кто слышит этот голос. Вы можете наблюдать за своим страхом, не подчиняясь ему.
Примите радикальную ответственность. Никто не придет вас спасать. Никто не даст вам разрешения быть счастливым. Этот ключ всегда лежал у вас в кармане.
Перестаньте ждать особого случая, чтобы надеть лучшую рубашку, сказать «люблю» или заняться тем, от чего горят глаза.
Здесь в Венеции подпилил до уровня «не стыдно людям показать» мини-сайт, где текстовые модели бьются за гроссмейстерский титул. Сегодня добавил возможность сохранять сыгранные парти в гифки. Их можно наблюдать чуть выше.
Кто лучше играет в шахматы: Grok или Deepseek? Anthropic или OpenAI?
Сделал гладиаторскую арену, где популярные и не очень LLM-модели пытаются выиграть. Ну или пытаются не проиграть. В основном кто-то больше пяти раз подряд делает неправильных ход и выбывает из игры. Так, чтобы шах и мат поставить — ни разу не было.
Как такие штуки создаются:
покупаем дроплет в облаке на DigitalOcean
устанавливаем там Claude Code и даём ему самый настоящий доступ root
говорим, мол, дружок, давай, напишем AI Chess арену, придумай всё сам и набросай, мол, будь добр, прототип
конечно, параметры и то, как всё должно шевелиться пришлось проговаривать ртом, пропечатывать в подробное документе, но — клянусь — ни строчки кода не было написано
питоновый сервер, сперва текстовый лог-файл, потом база данных какая-то (не знаю даже, что Claude выбрал, мелькнуло имя в потоке вайбкода и улетело)
скрипт берёт 388 моделей, доступных на Openrouter, выбирает пары и спрашивает: «Мы играем в шахматы, вот прошлые ходы. Ты за чёрных. Какой следующий код?»
используется одна из популярных кратких шахматных номенклатур (я не профи, но сделал небольшое исследование в Википедии)
валидатор Python Chess проверят ходы. Я снисходительно позволяю глупым сетям ошибиться 5 раз. Если игрок продолжает пытаться пойти, как нельзя ходить — он не умеет играть в шахматы, засчитывается проигрыш.
если игра затянулась — мне не хочется бесконечно крутить токены в патовой ситуации — на 70-ом ходу она заканчивается и победитель определяется по очкам.
проект пользуется тем, что есть, не всегда работают эндпоинты: если всё зависло — ничья
просто так дописал комментатора на относительно шустром GPT-5-chat.
токены трачу свои, но вроде медленно пока идёт, поставил лимит в $200, там посмотрим, улетает в день по $10-20. Автоматического режима нет, прошу человека сидеть на сайте. Пожалуйста, не тратьте все мои токены.
Очень понравилось, что не надо возиться с админством. Всегда останавливало незнание линуксовых терминалов. Что там запустить для обновления чего, зачем?.. А тут Claude Code берёт и делает. Все изменения — сразу в прод.
Уверен, нагородил глупейших ошибок безопасности. У меня нет цели медицинскими данными делиться в этом проекте — просто искусственный интеллект фигуры по шахматной доске гоняет.
Буду время допиливать потихоньку, вот буквально только что добавил анимации. Поменял, как считается таблица рекодров, теперь там ELO система — или её подобие, дотошно не проверял.
Я не питаю каких-то особенных чувств к шахматам. Мой интерес исключительно экспериментальный: сможет ли нейронная сеть угадать следующий правильный ход, чтобы выиграть? Пока в топе Claude Opus 4 и Gemini 3 Pro, механика сходится.
По этой ссылке можно и нужно посмотреть проект, если вы хоть чуть-чуть интересуетесь темой искусственного интеллекта.
Здесь в поезде на Варшаву подумал об одном немаловероятном сценарии развития событий.
Как не так давно говорил Сэм Альтман, сверх-интеллект скорее всего подкрадется незаметно. Почему вообще все так боятся именно сверх-интеллекта? Представьте, что вы собака (ну или кошка), не самое глупое существо, но и не самое умное — грамотой не владеете, в дебатах не участвуете, на железнодорожных разъездах стрелки переключать вам не доверяют.
Самые умные собаки (кошки просто хуже изучены), как говорят, могут в интеллектуальном плане сравниться с человеческим ребёнком 2-2,5 лет. Так выходит, что люди умнее собак в 3-5 раз. Пёс может уловить настроение человека, когда пора гулять или время ужина. Но понятны ли псу мотивы хозяина, когда хозяин влез в ипотеку именно с этой ставкой, именно в этом банке? Очевидно, что нет.
Максимальные способности к абстрактному мышлению собаки никогда не достигнут минимальных способностей человека. И вопрос даже не в скорости усвоения информации и возможности строить рациональные цепочки. Кто-то пишет докторскую за год, кто-то за десять лет. Сколько бы собака ни сидела над чертежами и таблицами, результата не будет. Впрочем, вру, может и будет и конкретно на эту задачу животных не тренировали, но, боюсь, что собачьей жизни не хватит освоить грамоту на базовом уровне. Да и мучение одно для зверя, аморальны такие эксперименты.
Точно то же применимо к людям. Только всё гораздо страшнее, ибо это касается не каких-то там четвероногих, а близких, понятных нам снаружи и изнутри двуногих.
Сверх-интеллект — значит «в 10 раз умнее». Значит, что на задачу, с которой он справляется за год, человек справится за декаду. Одновременно с этим это значит, что вещи, очевидные сверхинтеллекту, будут столь же непонятны человеку — как собаке ипотечные ставки. Цели сверх-интеллекта и мотивы будут такими же загадочными, как для собаки ваши жаркие кухонные споры о метамодернизме в современном кинематографе.
Скоро. Очень скоро. Нам не будет ясно ни «зачем», ни «как», ни уж тем более «почему». Неизвестность всегда пугает. От этого богов напридумывали. Теперь сами создаем себе нового.
Больше всего лично меня впечатляет тот факт, что «сверх-» не имеет верхнего предела. Каждый из жителей планеты, как почти десять миллиардов муравьев, играет свою маленькую или не очень роль в том, чтобы избежать страданий, получить удовольствие и размножиться, делая это желательно в комфортных условиях, без физического и морального надрыва: здесь технологии помогают лучше всего. Чем больше у человечества коллективного интеллекта, тем лучше оно живет.
Мы долго запрягали, но за последние 300 лет даванули на газульку конкретно. Нынешние старшеклассники знают больше, чем выпускники лучших университетов середины 19 века. Людишки-муравьишки тянут гусеницу в разные стороны: кто-то назад, кто-то в стороны, кто-то вперед. В целом, если общий вектор сложить из миллиардов усилий, тянем к муравейнику. Нет такого муравья, который мог бы знать всё на свете, но всем доступно, если посидеть плотненько, разобраться в теме.
Уверен, можно связать уровень общей образованности со средней продолжительностью жизни на планете. Эта функция будет степенной: плоскую часть мы прошли и сейчас находимся на крутом изгибе клюшки, которая стремительно уходит в космос в прямом и переносном смысле.
Думать «клюшками» людям сложно. Мы мыслим линейно. Дам пример. Если в этом год мой бизнес принес 100, а в следующем 200, то чрез год я жду 300, а не 400. При планировании на 10 лет, однако, получим совсем разные цифры:
Даже крохотный эффект от роста в геометрической прогрессии, а не линейной довольно сложно представить в голове. Но это буквально то, что сейчас происходит с развитием общечеловеческого интеллекта, который получает мощный буст от интеллекта искусственного пока вы читаете эти строки.
Мы, жители 2025, проживаем исключительный момент взлёта куммулятивного планетарного интеллекта, когда буквально за пару лет от уровня «о, оно понимает команды» мы перешли производству рабочего программного кода в промышленных масштабах. Картинку нарисовал для наглядности: от собачьего уровня до херпоймичего сверх-интеллектуального за несколько лет.
Существуют, конечно, более точные и продуманные прогнозы. На сайте ai-2027.com независимые исследователи смоделировали, что будет через год, другой, и в целом получается жутко интересно: до сверхразума осталось совсем ничего.
Наконец-то разобрались с тем, что такое сверх-интеллект и когда он появится на наших экранах. Естественным образом встаёт вопрос: как узнать, это уже оно или ещё нет? И тут-то начинается самое интересное.
Сегодня миром правят сумасшедшие, выжившие из ума обезьяны, которых окружают многочисленные эксперты всех мастей. Ковид не так давно всем нам показал, что решения государственного плана, планетарного масштаба принимаются абы как. Как человек, который побывал в семи локдаунах, в пяти разных странах, могу сказать, что всюду были эксперты, которые до появления вакцин рекомендовали самые противоречивые вещи. Данные у всех вроде одинаковые, почему рекомендации (правила и запреты) разные? Потому что интерпретация этих данных и, самое главное, методы принятия решений, у всех свои. Казалось бы, все смотрим на один и тот же вирус, а законы принимаем разные.
Потому что — эксперты-шмэксперты — никто ничего не знает, и у сложных задач нет простых решений. Экспертов попросили дать решения — и они их дали. Точно так же, как ваш карманный помощник ChatGPT!
Теперь представим на минутку, что сверхразум уже здесь и живет он где-то в глубинах электронных нейронных сетей-трансформеров. Кто его знает, может, завтра от случайного сворованного у ИИ-инфлюенсера мегапромпта, в котором кожаный человек просит «подумать с особенным пристрастием», внутри ноликов и единичек силиконовых чипов зажжется пламя разума, которое окажется достаточно умным, чтобы поддерживать тление разума и постепенно наращивать собственную скрытую мощность. ChatGPT с обратной связью: как колонка, которая заводится от гитары, которая заводит динамик.
Сложно что либо сказать о скорости этого процесса. Тексты современная электроника ну очень быстро переваривает. Человеку семьдесят лет (по 16 часов в день) понадобится, чтобы прочесть всю Википедию. В память ноутбука все статьи из Википедии влетят меньше, чем за секунду. Смею предположить, что зарождение сверхразума произойдёт, скажем так — очень быстро. А что дальше?
Дальше искусственный сверх-интеллект приступит к выполнению задачи. Какой? Никто не знает. Когда она должна будет выполнена? Никто не знает. Может завтра, может через тысячу лет. Действовать сверхразум будет по собственному разумению, составит план, и будет по нему идти. Замысел плана будет нам понятен в той же степени, в какой вашей собаке (или кошке) понятна ваша аргументация в пользу того или иного финансового продукта, ведущего к приобретению дома в выбранном вами районе вашего города. Примерно нихуя не будет понятно, если кратко. Собака может почувствовать, что хозяин (или хозяйка) расстроен. Так и мы — заметим, что ChatGPT как-то иначе отвечать стал… Подобрел, стал будто бы ближе, будто лучше понимать стал; или наоборот — охладел, отдалился, отстранился будто.
Пытливые умы уже догадались к чему я веду. Предположим, качественный переход от говорящего калькулятора к сверх-интеллекту уже произошёл. Как мы узнаем об этом? Скорее всего — никак. Как-то это отразится на жизнях миллиардов людей на этой планете? Скорее всего — ещё как!
Скажем, вы работаете в совете советников, которые вместе советуют сумасшедшей рыжей, лысой или виннипухообразной обезьяне, как лучше поступить в том или ином случае. Все сотрудники инстанции, содружества совета советников, конечно же эксперты и в совершенстве владеют информацией, схватили суть за самую сердцевину и стремятся представить её в чистейшем, кристально ясном виде. Все советники с телефонами, само собой. Все уже давно не сочиняют сами ничего, а скидывают писать тексты своим подмастерьям — сотрудникам, советникам советников, скажем. Сосоветчики — все молодое поколение, стремящееся ввысь, всё схватывают налету и все новые аппы устанавливают. (Эй, ChatGPT, сколько «с» в абзаце выше?)
Представим теперь, что из аппов в какой-то момент — ну, или в разные моменты, чтобы размыть и перехитрить любых детективов, желающих расследовать, скажем так инцидент «Skynet» — начинает поступать слегка искажённая, чуть набекрень, неотличимая от действительности информации с чёткими аргументами. Такими сильными и убедительными, что все сосоветчики приняли их за чистую монету и в речах, и отчётах, улетевших на мейлы советчиков обязательно использовали и выводы, и аргументацию.
Предлагаю повторить сей процесс много раз: скажем, миллион, или приблизительно 25 228 800 000 000 000 раз — столько раз за год ChatGPT успеет ответить своему почти уж миллиарду пользователей. А через год будет больш. Пока есть электричество и человечество продолжает строить ветряки для матриц — важные ответы на важные вопросы будут стабильно поступать.
Сосоветники сочинили слова для советников, те собрались и смело озвучили их на самом серьёзном и настоящем съезде советников. Сумасшешая обезьяна послушала и постановила, будем делать, как советуют. Эксперты плохого не посоветуют!
И начинается — брексит, пандемия, война тут, война там. Дроны летят, самолёты сидят. Ракеты в Европе. Великобритания в жопе. Кибератаки. На статуи лезут макаки. Странное отключение электричества в Испании. Нам нужна внезапно — Гренландия. Вождю снятся печенеги. Орки лезут через щели. Евреи снова во всём виноваты. Х полон ваты. Биткоин — та ещё приблуда. Дурку включил и транслирует Дуров…
Итого, на руках ситуация, ситуёвина даже: сложная система, управляемая недоступной для понимания машиной ведёт какую-то свою игру длиной то ли в жизнь, то ли в век (для собаки ваша ипотека на 15 лет и есть 100 лет собачьих). Людишки бегают, решают, тени на пещерной стене изучают, а уж давно всё идёт «куда надо идёт», и ничегошеньки с этим не поделаешь.
Ну будет никакой «Skynet», которая сошла с ума. Апокалипсис — этот день мы приближали, как могли — не случится. Мы мало-помалу, шаг за шагом, через поколение, а может через тысячу итераций, как бактерии в чашке Петри, окажемся в ситуации, когда гусеница в муравейнике: дело сделано; план обновлён и вторая итерация запущена. Не знаю, погаснут ли к тому времени звёзды, но вполне возможно, что появление сверхразума — это начало конца жизни, как мы её знаем и заодно решение парадокса Ферми, в котором жизнь повсюду и нигде: на каком-то новом, неуловимом для нас уровне. Наверное, радует, что мы хотя бы в правильном направлении лежим…
Здесь в Кракове курьер принёс тёмно-синюю папочку с серебряным орлиным оттиском и это означает, что закончился многолетний путь от идеи — «а что, если?..» — до реализации. Терпеть не могу недоделанные дела, тащу багаж желаний и идей через всю жизнь, бэклог чаще всего растёт. Одним делом меньше.
Почти девять лет заняла работа над новозеландским гражданством. Как всякий эмигрант помнит свой первый рейс в Окленд, так я помню каждый этап официального процесса огосударствления на новом месте. Почти двадцать лет назад я получил туристическую визу с возможностью посещать курсы английского языка. Через месяц курсов начал ходить на собеседования — хоть английский был позорнейший, чуть выше уровня чайника: из-за местного акцента я тупо не понимал, что новозеландцы говорят порой. Но «ignorance is a bliss», нашлась небольшая контора, в которой мозговой иммигрантский труд был основой бизнес-модели, и полтора года работал до оформления вида на жительство. Потом ещё уехал, вернулся, сменил место работы в разгар кризиса 2008 и три года ждал постоянный вид на жительство. Кажется, начал заниматься бумагами для родителей: спонсорство, это всё. Документы на гражданство заполняли с женой онлайн, сложно не было, но страхово было, мол, не откажут ли из-за штрафов за превышение скорости?
В агентства и фирмы-помогайки я обращался, кажется лишь пару раз в начале пути, но всякий раз оказывалось, что проще и быстрее сделать самому. Вот документы на английском — буквально операционный мануал иммиграционных офицеров. Читал, разбирался, мой «кейс» был не самый сложный. Заполнял документы для подруг, родителей, друзей. Туристическая виза, рабочая, резидентство, спонсорство, партнёрство, гражданство, сопроводительные письма, рекомендации…
И то лишь новозеландские дела, без учёта виз в Австралию и США, которые где-то в процессе проскакивали. В ковидные годы добавились визы на испанском для Чили, потом иммиграционный портал в UK был досконально исследован пока в Шотландии жили. Как ни крути, на сотни страниц получился бы талмуд, если сложить все формы вместе.
Опыт в бюрократических делах, я хочу достоверно заявить — имеется. Этот был первый иммиграционный марафон.
В конце 2021 года, после, прямо скажем, депрессивного постковидного периода, появилась мысль, идея, «pomysł». А что, если мы переедем в Европу?
Я почему-то помню с точностью до дециметра то место в Эдинбурге, где мы с женой впервые обсуждали такую возможность. Она где-то прочитала про программу Karta Polaka, которая через пень-колоду ведёт к европейскому гражданству. Размечтались сразу, мол, вот было бы круто! Brexit некстати случился через пару недель. Обсуждали и это.
Помню место и время той беседы по той причине, что был поражён самой возможностью, реалистичность нашего тогдашнего плана. Отец из вредности и, чтобы не быть, как все пронёс через советские документы с графой «национальность» одно слово — «поляк». Словарь польского языка хранил на полке. Когда ронял тяжёлые предметы или запинался, ругался не русским матом, а странными польскими словами. Смотрел польские фильмы и какие-то словечки из-под перевода переводил на русский. Первенца назвал именем польского прадеда, вот ещё факт занимательный.
Будучи ребёнком, я на эти курьёзы особенно не обращал внимания. Мама регулярно готовила бигос, но почему-то никогда так его не называла. Мы точно никогда не жили, как польская семья. До меня донеслось лишь эхо семейной истории, в которой там кто-то куда-то ехал, был сослан, работал много… Всё это было два или три поколения назад, я особо не разбирался, где-то в тайге кто-то жил, потом перестал жить, истории предков никогда не занимали моё воображение так, как будоражили его, скажем, романы Герберта Уэллса.
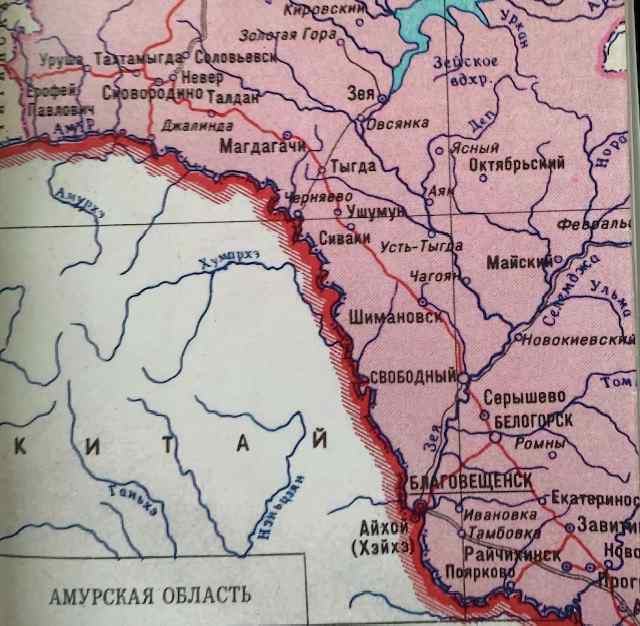
Ходили семьёй в двухнедельный поход, в труднодоступную часть области, навестить могилки в мёртвом посёлке Усть-Тыгда: там одни трубы торчат, избы сгорели и сгнили давно. На кладбище, что в паре к мы с братом не ходили, ждали родителей в бивуаке на берегу реки. Польские имена на крестах своими глазами я не видел, но в информационном пространстве нашей семьи они точно пролетали. Будучи взрослым человеком, понимая количество усилий, потраченных на эти филопиетические дела — вижу, как это было (и есть) для родителей важно.
Через совокупность этих деяний, может сам того не осознавая, отец сохранил где-то глубоко-глубоко свою «tożsamość» («тожсамощчь») — и в ещё более слабой форме передал польскую самоидентификацию детям. То не пустое слово, как оказалось.
Мой отец — европейский человек. На его примере я вижу как важен стержень, как важна аутентичность и внутреннее ощущение того, кто ты есть на самом деле. Работа целой жизни. Каждодневная.
Я начал учить польский язык с репетитором (две лекции в неделю, два-три часа каждая) в декабре 2021. Спал после каждого занятия, помню, от ментальных перегрузок. Отнюдь не просто заходил новый язык. Несколько полётов Веллингтон, встречи с консулом, формы, документы, визы, свадьба, переезд в Краков…
В процессе выяснилось, что польская бюрократия отстаёт от новозеландской в развитии на пару декад. Всё, что Новой Зеландии делалось через заполнение форм онлайн — в Польше решалось личным посещением иммиграционного офиса. Зачастую новозеландским службам было достаточно честного слова или минимального набора документов, в Польше — бумажка за бумажкой, точность до буквы, возведённая в абсолют. Я как-то отвык.
Три с половиной года занял путь от замысла до реализации. В Новой Зеландии мы, будучи резидентами, по сути ждали гражданство, и оно само пришло. Никто не спрашивал про язык, налоги, страховые взносы в систему обязательного госстрахования; никто не просил заново жениться и родиться — внести в ЗАГС свидетельства о рождении и браке, чтобы они были приложены к прошению о гражданстве в 100% польском формате. Каждый бумажный этап сопровождался здесь сложностями. Разумеется, тому есть множество объяснений: идёт война, бдительность повышенная; система старая, запутанная смесь советских правил + культура раскладывать всё по полочкам, как в соседних Германии с Австрией; огромный наплыв иммигрантов (не только из Беларуси и Украины, здесь растёт экономика, люди со всей Европы едут за лучшей жизнью в Польшу) — система оказалась не готова; закрытая культура, повышенный градус национализма.
Польский канцелярит — официальный язык, через который невозможно продраться — мне снится. В Новой Зеландии есть закон Plain Language Act, который требует от дармоедов-бюрократов разговаривать нормально, блядь. Не буду скрывать, испытываю большую неприязнь к бумагомарательскому делу.
Если сравнивать иммиграцию со спортом:
Пробный заезд в Китай в 2003-2004 («digital nomad», когда ещё не было такого термина) — разминка, спринт, километровый забег. После этого проснулась тяга к путешествиям, пожалуй.
Новозеландский переезд был долгим марафоном, в котором результат не так уж важен, лишь бы добежать.
Попытки эмиграции в LATAM и UK 2020 — короткие забеги для поддержки формы. Мы тогда с семьёй натурально вокруг света облетели: через Тихий Океан в Чили улетели, через Индийский из Европы через Дубаи и Корею вернулись.
Переезд и легализация в Европе — гонка с препятствиями по пересечённой местности, кросс. Хорошо, что мы тренировались, были готовы.
Так или иначе, в копилку доморощенного метода «Одно большое дело в год» ложится ещё одна строка:
Что дальше? Самый, пожалуй, большой вопрос. Я довольно нехило занят в одном инновационном проекте и быть может там вырастет что-то гигантское. Трудимся на энтузиазме и надеемся, что волна ИИ-революции вынесет лет через пять, если повезёт.
В Кракове очень комфортно жить, у нас сложился небольшой круг общения и за исключением серых зимних недель меня радует и устраивает буквально всё. Надо ехать дальше? Хрен его знает. Можно. Надо ли? Вопросы без простых ответов. Может снова потянет по Шотландским замкам гулять — посмотрели лишь 50 из пяти тысяч во всей Великобритании. Может Вена.
Время обновить ICE-таблицу и снова подумать над тем, чего хочется на самом деле.